This week’s Riddler Classic concerns some funky dice rolls based on Dungeons & Dragons.
Edit: Fun! This solution was mentioned in the article describing the answer. You can read the write-up here.
Here’s the text of the puzzle, and my solution below.
The fifth edition of Dungeons & Dragons introduced a system of “advantage and disadvantage.” When you roll a die “with advantage,” you roll the die twice and keep the higher result. Rolling “with disadvantage” is similar, except you keep the lower result instead. The rules further specify that when a player rolls with both advantage and disadvantage, they cancel out, and the player rolls a single die. Yawn!
There are two other, more mathematically interesting ways that advantage and disadvantage could be combined. First, you could have “advantage of disadvantage,” meaning you roll twice with disadvantage and then keep the higher result. Or, you could have “disadvantage of advantage,” meaning you roll twice with advantage and then keep the lower result. With a fair 20-sided die, which situation produces the highest expected roll: advantage of disadvantage, disadvantage of advantage or rolling a single die?
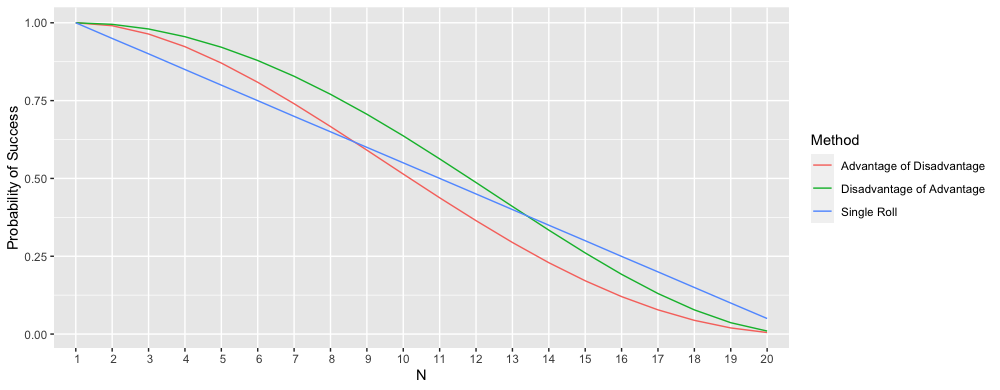
Extra Credit: Instead of maximizing your expected roll, suppose you need to roll N or better with your 20-sided die. For each value of N, is it better to use advantage of disadvantage, disadvantage of advantage or rolling a single die?
If your goal is to maximize your result, it turns out the best methods in expectation are disadvantage of advantage, rolling a single die, and disadvantage of advantage in that order.
For all $N \in {1, \dots, 20}$ things get a little more interesting. Disadvantage of advantage weakly dominates advantage of disadvantage for any $N$ in this range. The battle between disadvantage of advantage and the single roll is won by our reigning champ so far—disadvantage of advantage—until $N \geq 14$, where a single roll beats it out.
I wrote up some quick Monte Carlo simulations to show the results, but as a sanity check and to illustrate some logic, let’s work analytically through the simplest method, a single roll. For a discrete random variable $X$ with finite realizations $x_1, x_2, \dots, x_k$, with each realization occurring with probability $p_1, p_2, \dots, p_k$, its expected value can be written as:
\[\text{E}[X] = \sum_{i = 1}^{k} x_i p_i = x_1p_1 + x_2p_2 + \dots + x_k p_k\]What does this mean? Basically we’re taking a weighted average of each value based on how probable each value is. To ground this in simpler terms, for a 20-sided fair dice, $p_i \forall i = \frac{1}{20}$ because each outcome is equally likely, and $x_i = i$, because rolling a face of $i$ simply corresponds to the value given by that face. Thus, the expectation of a fair, 20-sided die is:
\[\text{E}[X] = \sum_{i = 1}^{20} x_i p_i = 1 \frac{1}{20} + 2 \frac{1}{20} + \dots + 20 \frac{1}{20} = \frac{210}{20} = \frac{21}{2}\]Since the sum of the integers from 1 through 20 is 210, we can simply divide that value by 20, yielding 10.5.
To code this up in R, let’s first set a random number seed and the number of simulations we’ll be working with, 1 million here:
set.seed(05162020)
sims <- 10^6
We can simulate rolling a fair, 20-sided die by creating an object die that is a vector of the integers from 1 through 20, and sampling from it once with replacement.
die <- 1:20
sample(die, 1, replace = TRUE))
Let’s repeat this for the number of simulations are store each roll in a vector of the same length as the total number of simulations.
single_roll_results <- sapply(1:sims, function(s) sample(die, 1, replace = TRUE))
Taking the mean will give us, as expected, 10.5 (with some rounding error).
mean(single_roll_results)
Before working with advantage of disadvantage or vice versa, let’s get to the smallest layer of this matryoshka doll and simulate a roll of advantage (disadvantage). To do this, we can sample from die twice with replacement and keep the maximum (minimum) value of the two rolls.
# advantage
max(sample(die, 2, replace = TRUE))
# disadvantage
min(sample(die, 2, replace = TRUE))
To model advantage of disadvantage (disadvantage of advantage), let’s create a function that performs disadvantage (advantage) twice and takes the maximum (minimum) value of those two methods.
# advantage of disadvantage
ad_of_dis <- function() {
roll_1 <- min(sample(die, 2, replace = TRUE))
roll_2 <- min(sample(die, 2, replace = TRUE))
return(max(roll_1, roll_2))
}
# disadvantage of advantage
dis_of_ad <- function() {
roll_1 <- max(sample(die, 2, replace = TRUE))
roll_2 <- max(sample(die, 2, replace = TRUE))
return(min(roll_1, roll_2))
}
Not too bad! If we repeat these a million times we can reach our results:
ad_of_dis_results <- sapply(1:sims, function(s) ad_of_dis())
mean(ad_of_dis_results)
dis_of_ad_results <- sapply(1:sims, function(s) dis_of_ad())
mean(dis_of_ad_results)
The expected value of advantage of disadvantage is around 9.83, while the expected value of disadvantage of advantage is around 11.17.
Thus, the method that produces the highest expected roll is disadvantage of advantage, followed by rolling a single die, followed by advantage of disadvantage. It’s interesting—if intuitive—to note that they are symmetric around the value for rolling a single die, since $11.17 - 10.5 = 10.5 - 9.83$.
Visually, we can graph each of the values that the methods can output on the x-axis and the probability that a particular method yields a particular value. In technical terms, this is the probability mass function. I include this below, along with the dashed lines that represent the aforementioned expected value figures. Before I’m attacked by statisticians, yes, the figure is not supposed to be connected via a smooth line given that we’re dealing with discrete random variables. But it looks much prettier and is easier to interpret like so.

How about the extra credit? Given what we’ve already done, that’s not too bad to tack on. I create a new data frame where the rows are the integers from 1 through 20, and then for each $N$ for each method, take the number of times the method yielded a result greater than or equal to the $N$ of interest, divided by the total number of simulations.
generalized <- as.data.frame(matrix(1:20, ncol = 1))
names(generalized) <- "N"
generalized$`Advantage of Disadvantage` <- NA
generalized$`Disadvantage of Advantage` <- NA
generalized$`Single Roll` <- NA
for (n in 1:20) {
generalized[n, 'Advantage of Disadvantage'] <- sum(ad_of_dis_results >= n)/sims
generalized[n, 'Disadvantage of Advantage'] <- sum(dis_of_ad_results >= n)/sims
generalized[n, 'Single Roll'] <- sum(single_roll_results >= n)/sims
}
Visually, we can graph the results and see for a given $N$ where a particular method outperforms another. In technical terms, this is a kind of cumulative distribution function of our random variables. Again, note that since $N$ is discrete, these lines shouldn’t technically be smooth. Whereas the traditional CDF represents the probability that $X$ will take a value less than or equal to $x$, this represents the probability that $X$ will take a value greater than or equal to $x$.
And we’re done! Now the word “advantage” sounds so silly to me.
The code to produce the plots is below.
# make pmf
main_q <- as.data.frame(c(ad_of_dis_results, dis_of_ad_results, single_roll_results))
names(main_q) <- "Value"
main_q$Method <- c(rep("Advantage of Disadvantage", nrow(main_q)/3), rep("Disadvantage of Advantage", nrow(main_q)/3), rep("Single Roll", nrow(main_q)/3))
library(dplyr)
main_q <- main_q %>%
group_by(Method, Value) %>%
tally()
main_q$Prob <- main_q$n/sims
library(ggplot2)
ggplot(main_q, aes(x = Value, y = Prob, group = Method, colour = Method)) +
geom_point(size = 1) +
scale_x_discrete(limits = 1:20) +
scale_y_continuous(name = "Probability") +
geom_vline(xintercept = mean(ad_of_dis_results), colour = "#F8766D", linetype = "dashed") +
geom_vline(xintercept = mean(dis_of_ad_results), colour = "#00BA38", linetype = "dashed") +
geom_vline(xintercept = mean(single_roll_results), colour = "#619CFF", linetype = "dashed")
# make extra credit figure
library(reshape2)
generalized <- melt(generalized[,2:4])
names(generalized) <- c("Method", "Prob")
generalized$N <- rep(1:20, 3)
ggplot(generalized, aes(x = N, y = Prob, group = Method, colour = Method)) +
geom_line() +
scale_x_discrete(limits = 1:20) +
scale_y_continuous(name = "Probability of Success")